Symfony Error Monitoring mit Monolog und Elasticsearch

- Wie man Elasticsearch und Kibana mit Debian 12 aufsetzt
- Die Konfiguration von Symfony-Applikationen um an ELK Logs zu übermitteln
- Die Konfiguration von Index-Patterns in Kibana
Als Web-Entwickler steht man oft vor der Herausforderung, dass Fehler in irgendwelchen Logs untergehen und übersehen werden. Doch gerade um wichtige Platzierungen bei Suchmaschinen zu halten, sollten möglichst keine Fehler das Nutzererlebnis beeinträchtigen.
Viele Fehler können im Vorfeld bereits durch gute Tests identifiziert werden, es kann aber dennoch immer mal vorkommen, dass ein Fehler durch die Überprüfung rutscht. Doch wenn der Fehler erstmal in der produktiven Anwendung ist, ist es umso wichtiger diesen schnell identifizieren zu können. In den nachfolgenden Abschnitten wollen wir Ihnen zeigen, wie Sie ganz einfach ein Error-Monitoring mit monolog und Elasticsearch (genauer dem ELK-Stack) aufbauen können um Ihre Symfony-Anwendung zu überwachen.
Das Paket monolog sollte einem als Symfony-Entwickler bereits bekannt vorkommen. Das Paket ist mit über 140 Mio. Installationen sehr weit verbreitet und wird auch von Symfony für das Logging empfohlen. Elasticsearch bzw. der ELK-Stack (bestehend aus Elasticsearch, Logstash und Kibana) dürften eher den Systemadministratoren bekannt vorkommen.
Aufbau des Monitorings
Um das Monitoring überhaupt nutzen zu können müssen wir erstmal den ELK-Stack aufsetzen. Vom ELK-Stack benötigen wir aber nur Elasticsearch und Kibana. Wir werden daher auch nur diese beiden Programme installieren. Eventuell macht es aber Sinn weitere Pakete wie Filebeat und Logstash zu installieren, sollte die Instanz für weitere Dienste abseits von Symfony verwendet werden. In der nachfolgenden Anleitung verwenden wir das Betriebssystem Debian 12 (Bookworm), unter anderen Distributionen oder Versionen kann es sein, dass bestimmte Inhalte nicht vorhanden sind oder Befehle nicht funktionieren. Im Rahmen des Tutorials zeigen wir nur die Installation einer einzelnen Elasticsearch-Node, für größere Installationen und mehr Ausfallsicherheit sollte über ein Cluster nachgedacht werden.
System-Voraussetzungen
| Arbeitsspeicher | min. 8GB (je nach System ggf. 64GB und mehr) |
| CPU | min. 4 Kerne |
| Festplatte | min. 50GB (für kleinere Umgebungen), für größere Umgebungen sollten SSDs für bessere I/O Performance verwendet werden |
Installation und Konfiguration von Elasticsearch
Bevor Sie mit der Installation beginnen können, sollten Sie das System aktualisieren:
apt update
apt upgradeUm Elasticsearch installieren zu können, müssen wir das Repository von Elastic hinzufügen. Hierfür muss zuerst der GPG-Key von Elasticsearch importiert werden, anschließend muss noch das Repository hinterlegt werden:
apt install curl gnupg2 -ycurl -sL https://artifacts.elastic.co/GPG-KEY-elasticsearch | gpg --dearmor > /etc/apt/trusted.gpg.d/elastic.gpgecho "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | tee /etc/apt/sources.list.d/elastic-7.x.listNun kann Elasticsearch ganz einfach via apt installiert werden, nachdem mit apt update die Repositories neu geladen wurden:
apt updateapt install elasticsearchNach der Installation müssen noch ein paar Konfigurationen vorgenommen werden, damit Daten an Elasticsearch gesendet werden können.
Hierzu kann in der Datei /etc/elasticsearch/elasticsearch.yml folgende Konfiguration übernommen werden:
cluster.name: <Clustername der Applikation>
network.host: <Host-Adresse des Servers>
http.port: 9200
bootstrap.memory_lock: true
discovery.type: single-nodeEventuell sind Teile dieser Konfiguration bereits vorhanden, in diesem Fall können Sie die Zeilen einfach überschreiben.
Doch was genau bedeuten die einzelnen Werte überhaupt?
- cluster.name: Der Name des Clusters (In unserem Fall unserer Instanz) als Kennung (Sie haben die freie Wahl bei der Benennung)
- network.host: Die Netzwerkadresse des Servers, damit Elasticsearch über diese erreichbar ist. Im Normalfall start Elasticsearch ansonsten nur auf dem Lokalhost (127.0.0.1)
- http.port: Mit dem expliziten setzen des Ports verhindern wir, dass Elasticsearch sich den ersten freien Port ab 9200 auswählt. So ist der Port zuverlässig auf 9200.
- bootstrap.memory_lock: Verhindert, dass Elasticsearch SWAP verwendet und dadurch langsamer wird
- discovery.type: Setzt in unserem Fall das Cluster auf den Typ single-node, da wir keine zusätzlichen Server in das Cluster einbinden wollen
Anschließend können wir Elasticsearch als Service aktivieren und startklar machen:
service enable --now elasticsearch
Um zu überprüfen, ob Elasticsearch läuft, können wir den Status mit service status elasticsearch abfragen.
Um gänzlich zu überprüfen, können wir nun zur Schnittstelle unter http://IP-Adresse:9200 navigieren. Die Ausgabe sollte dort ähnlich wie hier aussehen:
{
"name" : "debian12",
"cluster_name" : "syntaxphoenix-demo",
"cluster_uuid" : "HJhGJdjbTAWXku4prm2bZQ",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Installation und Konfiguration von Kibana
Um unsere gesammelten Fehler auch ansehen zu können, benötigen wir Kibana. In unserem Beispiel installieren wir Kibana auf dem selben Server wir Elasticsearch. Grundsätzlich können Sie Kibana aber auch auf einer eigenen Instanz installieren.
Um Kibana nun zu installieren müssen wir zuerst das Paket über apt mit folgendem Befehl installieren:
apt install kibana
Standardmäßig läuft Kibana auf 127.0.0.1:5601,
daher stellen wir die Adresse auf unsere erreichbare Adresse des Servers um. Für beide Dienste empfiehlt es sich aber einen nginx oder haproxy als proxy davor zu setzen. Auch um den Traffic per SSL zu verschlüsseln.
Für Kibana nehmen wir daher noch folgende Änderungen in /etc/kibana/kibana.yml vor:
server.host: "<Host-Adresse des Servers>"
elasticsearch.hosts: ["http://<Host-Adresse des Servers>:9200"]
Kibana muss nun nurnoch wie Elasticsearch als Service aktiviert werden, hierzu müssen wir folgenden Befehl verwenden:
service enable --now kibana
Sollte noch eine Firewall wie z.B. ufw installiert sein, müssen die Ports für Elasticsearch und Kibana entsprechend geöffnet werden.
Anschließend sollten wir, wenn wir http://<Adresse unseres Servers>:5601 aufrufen, folgendes sehen:
Nun ist unser Server mit Elasticsearch und Kibana erfolgreich aufgesetzt und wir können entsprechend mit der Konfiguration innerhalb unserer Symfony-Anwendung starten.
Konfiguration der Symfony-Anwendung
Innerhalb der Symfony-Anwendung müssen wir nur wenig Anpassen, damit wir mit Elasticsearch kommunizieren können.
Zuerst müssen wir hierfür sicherstellen, dass monolog bzw. das monolog-bundle installiert ist und es ansonsten mit composer installieren:
composer install "symfony/monolog-bundle"
Anschließend können wir den ElasticsearchLogstashHandler konfigurieren. Dieser sendet unsere logs direkt zu Elasticsearch und formattiert diese wie Logstash.
Hierzu müssen wir den Service zuerst in der services.yaml unserer Applikation hinterlegen:
Symfony\Bridge\Monolog\Handler\ElasticsearchLogstashHandler:
arguments:
$endpoint: '%env(ELK_ENDPOINT)%'
$index: "<Name unserer Applikation>"
$client: null
$bubble: true
Als Index hinterlegen wir den Namen unserer Applikation, sodass wir diese später suchen können. Bei uns z.B. syntaxphoenix-homepage. Den Endpunkt setzen wir auf die Variable ELK_ENDPOINT, welche konfigurierbar über die .env-Datei ist. Dies ist hilfreich um auf Test-Servern eine andere ELK-Stack-Instanz verwenden zu können, sodass die Production-Logs nicht mit mit Test-Logs gemischt werden.
In der .env-Datei würde die Zeile dann wie folgt aussehen:
ELK_ENDPOINT=<Adresse unserer Elasticsearch-Instanz, inklusive Protokoll>Die Adresse könnte dann z.B. https://elk-prod.yourwebsite.com sein.
Um nun auch monolog richtig zu konfigurieren müssen wir dort den ELK-Handler hinterlegen. Im Normalfall sollten wir nur Logs speichern wollen, wenn wir die Anwendung produktiv gebaut haben (Für Test-Server und Produktiv-Server). Daher erstellen wir die monolog.yaml im Verzeichnis /config/packages/prod. Um zu verhindern, dass die Anwendung durch die Anfragen verlangsamt wird und damit nur einmal pro Anfrage alle Daten an Elasticsearch gesendet werden, sollte ein Finger-Crossed-Handler oder ein Buffer-Handler vor dem ElasticsearchLogstashHandler verwendet werden. Wir verwenden hier ersteres:
monolog:
handlers:
logfile:
type: rotating_file
path: "%kernel.logs_dir%/%kernel.environment%.log"
level: debug
max_files: 14
main:
type: fingers_crossed
level: debug
channels: ["!event"]
handler: elklogger
action_level: error
excluded_http_codes: [404, 405]
buffer_size: 50
elklogger:
type: service
id: Symfony\Bridge\Monolog\Handler\ElasticsearchLogstashHandler
In unserer Konfiguration setzen wir zusätzlich auf eine rotierende Logfile, damit logs im Notfall auch über die Verzeichnisse des Servers erreichbar sind, sollte es Probleme mit Elasticsearch geben. Zusätzlich senden wir nur alle Logs einer Anfrage, wenn ein Log-Eintrag mit Level ERROR vorhanden ist. Dies kann unter action_level im fingers_crossed-Handler angepasst werden. Alle normalen Anfragen ohne das entsprechende Action-Level werden aber weiterhin in den Logfiles gespeichert.
Die Konfiguration unserer Applikation für Elasticsearch ist nun abgeschlossen. Nun können wir in Kibana über das Burger-Menu auf der linken-Seite zur Seite Discover (Unter dem Reiter Analytics) navigieren. Die Seite sollte wie folgt aussehen:
Damit wir nun auch Einträge finden können, müssen wir sogenannte Index-Patterns angeben. Diese entsprechen dem Wert, welchen wir in unserer services.yaml für $index beim ElasticsearchLogstashHandler angegeben haben. Index-Patterns können wir konfigurieren unter <Kibana-Url>/app/management/kibana/indexPatterns. Hier können wir über den Button Create index pattern ein Pattern anlegen. Alle Pattern sollten mit einem Sternchen (*) enden. Als Timestamp-Field kann das Feld @timestamp ausgewählt werden. Sollte das Pattern noch nicht existieren, aber Daten dafür vorhanden sein, kann dies nun angelegt werden.
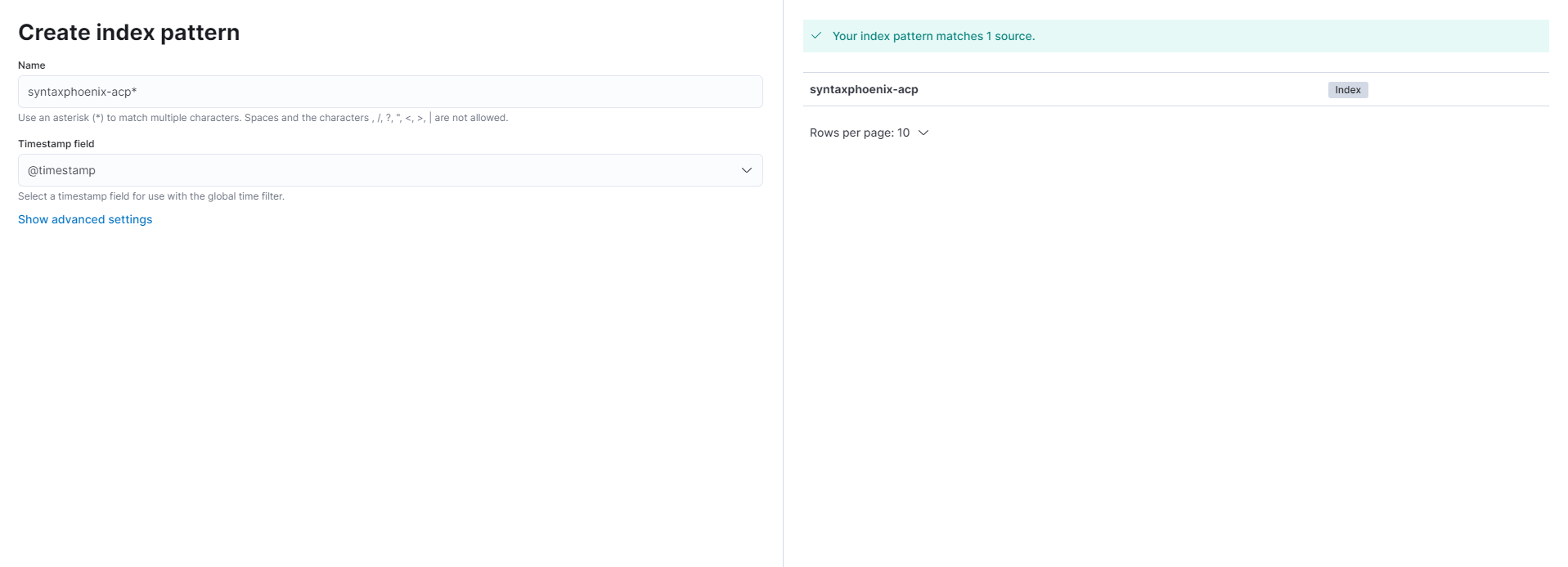
Nun können wir uns unsere Logs über Discover ansehen. Als Index-Pattern können wir nun unser gewähltes Index-Pattern auswählen. Sollten alle Anwendungen gleichzeitig angezeigt werden, so kann man dies realisieren, indem man das Index-Pattern * anlegt. So werden alle Index-Pattern via Wildcard geladen.



